Julian Yolles
March 24, 2019
Gone are the days when scholars of Ancient Greek and Latin literature relied solely on a prodigious memory and a printed library of classical texts, commentaries, and reference works. Digitized texts and new tools for textual analysis supplement traditional approaches. These methods do not require a physical library, and they promise to save time and to produce new insights.
The Tesserae Project seeks to take advantage of digital corpora to enable the user to find connections between texts. Its web interface allows users to search two texts or corpora from Greek and Latin literature for occurrences of two or more shared words within a line or phrase.
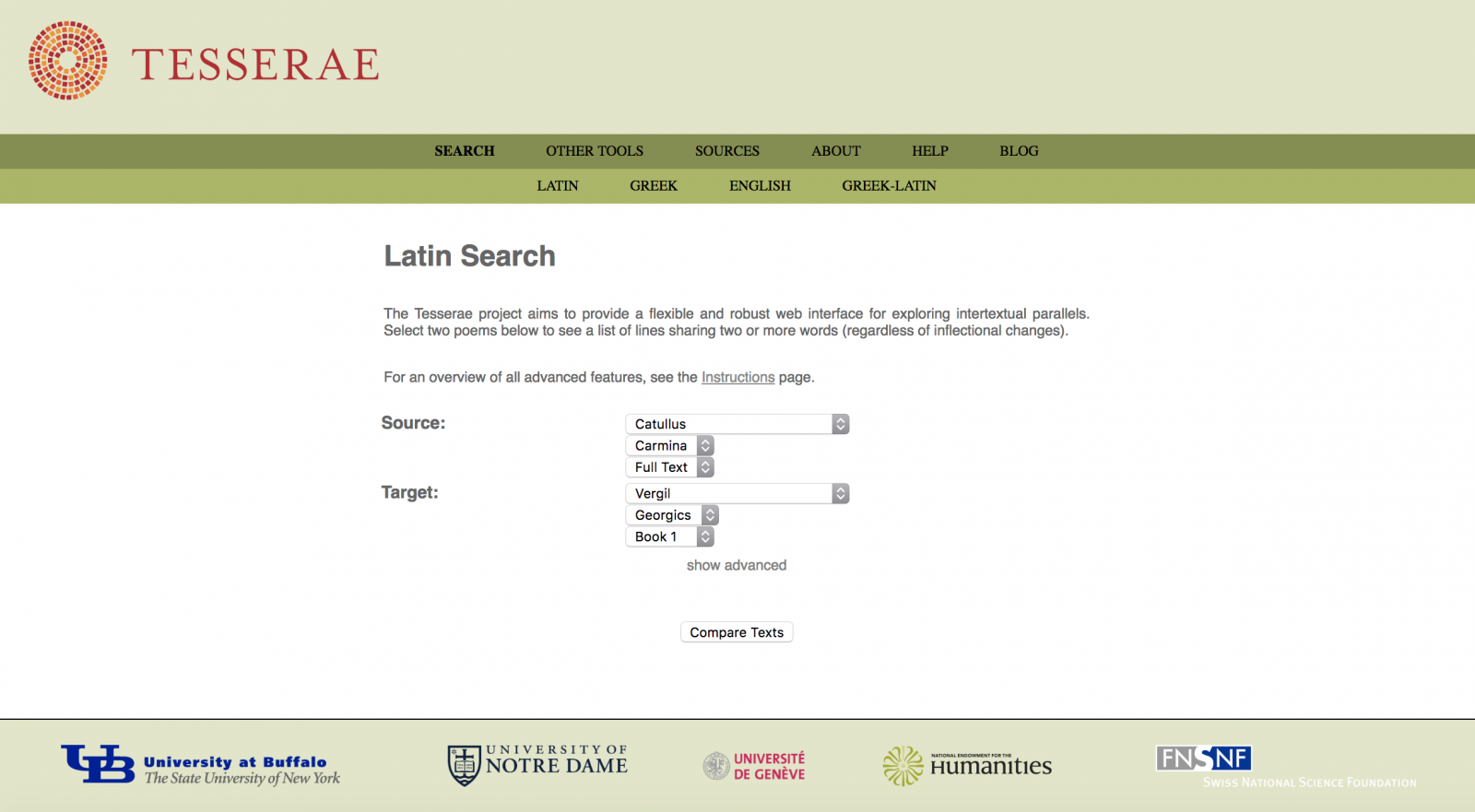
Screenshot of the homepage for the Tesserae Project.
For example, one could search for correspondences between Apuleius’ Apologia and a speech of Cicero, assess the extent to which Apollonius of Rhodes followed Homeric diction, or identify Juvenalian tendencies in Jerome’s letters. One could even compare Greek and Latin texts and examine, for instance, how Sallust used Thucydides. While one could (and still should) turn to commentaries and specialized studies, Tesserae performs a focused analysis of two (sets of) texts, allowing the testing of long-held scholarly assumptions and the identification of new relationships. Moreover, since some texts included in Tesserae’s corpus have not received dedicated studies and commentaries, users can produce entirely new insights.
The Search menu gives the user the option to search in Latin (the default), Greek, English texts, and in both Latin and Greek texts. The number of Latin texts available (104, not counting authors listed more than once) is the most extensive, including not only classical authors but also an impressive range of Late Antique writers, and a few (Early) Modern figures such as Melchior de Polignac and Francis Glass, author of an early nineteenth-century biography of George Washington. Tesserae also offers a decent number of Greek authors (71), including the mainstays of the classical curriculum and a few early Jewish (Flavius Josephus) and Christian writers (e.g., Clement, Basil, Eusebius). The English search option, labeled as “untested,” offers eight authors/texts, including Shakespeare, Swift, and the World English Bible.
As the section on Sources explains, the corpus of texts is compiled from an assortment of electronic databases, including The Latin Library, The Perseus Project, DigilibLT, the Open Greek and Latin Project, Musisque Deoque, and the Corpus Scriptorum Latinorum. An overview of sources for each text is given, including, where available, information about the print source of the electronic text. The user should be aware that the texts have been modified “by changing the markup” and by making “superficial changes to orthography,” and thus should not be cited as representations of the published texts without double checking.
The Basic Search function allows the user to select a Source and a Target text. Source represents the text alluded to, Target the alluding text. This selection impacts only the order in which the search results are presented, not the search itself. In other words, the algorithm compares two texts for similarities, then displays the results in the selected order to give users the impression of priority or influence. Selecting Tacitus’ Annals as Source and Sallust’s Catiline as Target will simply cause Tesserae to render the results in an anachronistic order, but the corresponding passages will be the same as when the order is reversed.
Selecting an author populates another dropdown list of titles. There are some limitations in selecting authors and texts. If one wished to find evidence of Vergilian allusions in the works of Tertullian, for example, the user would be required to perform separate searches of all combinations in each one of the authors’ works. One cannot compare the entire Vergilian corpus with all the works of Tertullian at once. Instead, Tesserae is designed to perform more focused analyses, which can produce powerful results.
To take full advantage of the features, one should use the Advanced Search option (click “show advanced” on any search page) and read the instructions provided. Users can then specify a range of parameters, most importantly, whether to search by
- exact word (string)
- lemma (disregarding inflection or conjugation)
- semantic match (based on the English dictionary headwords of the lemmata, thus including synonyms and related words)
- lemma + semantic match (a combination of the previous two)
- sound (trigrams: i.e., any combination of three letters occurring in both texts would be flagged).
The user can filter out the noise and limit the results, for instance by specifying the number of stopwords, thus eliminating highest-frequency words from results. There are several other ways to fine-tune results and to customize the order in which they are displayed. By default, results are ordered by the score Tesserae assigns each correspondence (in decreasing order), based on the frequency of rare words. Moreover, results can be exported as a tab-separated *.txt, *.csv, or *.xml file type.
Some examples will demonstrate the benefits and limits of Tesserae. It catches the allusion to Aeneid 2.557 (iacet ingens litore truncus) at Lucan, Bellum Civile 8.698–9(litora Pompeium feriunt, truncusque vadosis / huc illuc iactatur aquis), using the default settings, as long as one sets the unit to “phrase.”
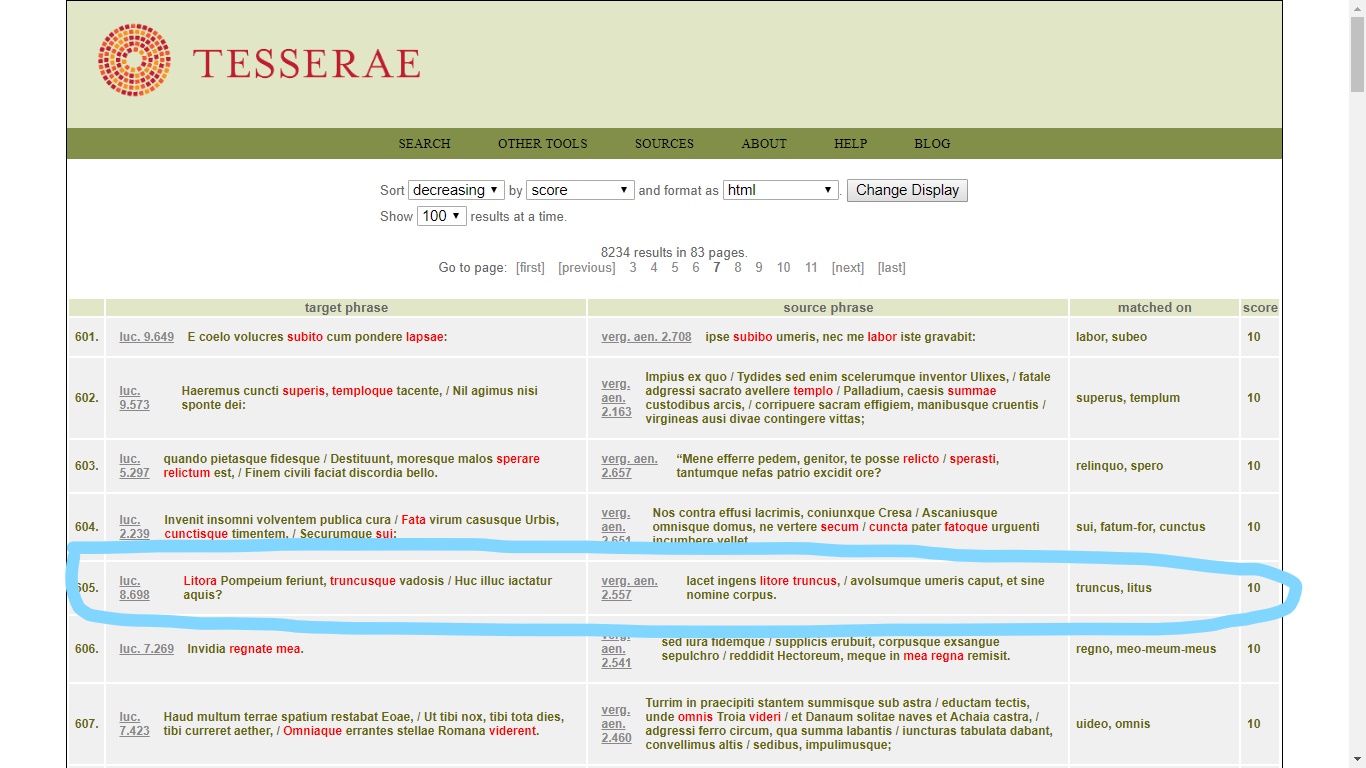
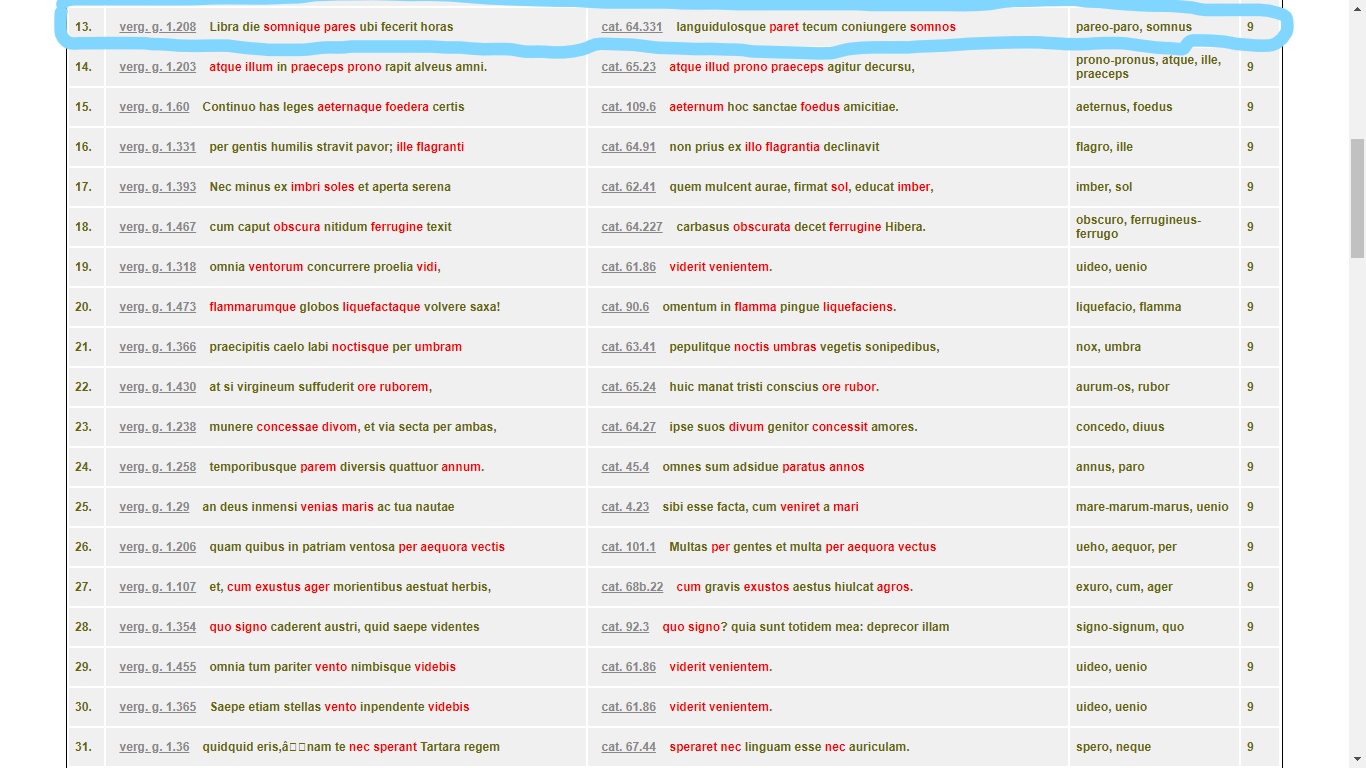
It even spots the reference to the same Vergilian passage at Lucan 1.685–6 (hunc ego fluminea deformis truncus harena / qui iacet, agnosco).Yet Tesserae also identifies many parallels which seem to me not meaningful, or rather not to be parallels at all. Since it cannot distinguish between homographs, the semantically unconnected words pares at Vergil, Georgics 1.208 (Libra die somnique pares ubi fecerit horas) and paret in Catullus 64.331 (languidulosque paret tecum coniungere somnos), are considered a match with a score of 9 (a score of 6 and above is considered “more likely to be interesting”).
Tesserae does not replace the human eye, nor is it particularly well-suited to suss out the subtler allusions, or even fairly obvious allusions that do not depend on close verbal correspondence. It fails, for example, to spot Vergil’s reminiscence of Lucretius 1.117–19 (Ennius ut noster cecinit, qui primus amoeno / detulit ex Helicone perenni fronde coronam / per gentes Italas hominum quae clara clueret) at Georgics 3.10–12 (primus ego in patriam mecum, modo vita supersit, / Aonio rediens deducam vertice Musas; primus Idumaeas referam tibi, Mantua, palmas), due to the lexical variation. For identifying these types of allusions, traditional exegesis remains indispensable. Instead, Tesserae can help identify patterns of speech across texts, and in a matter of seconds presents a multitude of starting points for more in-depth research.
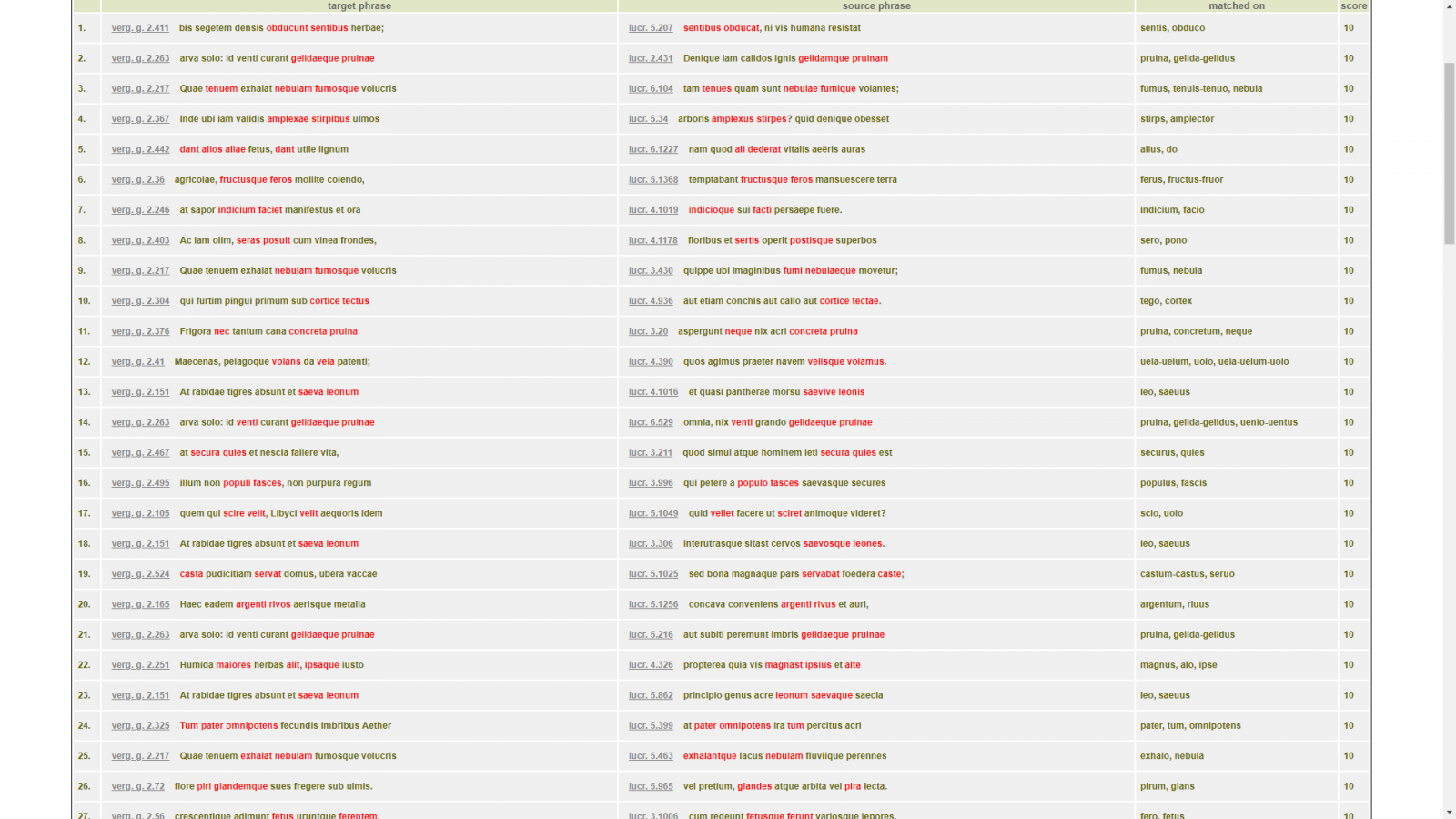
Even a cursory Tesserae comparison between Vergil, Georgics 2 and Lucretius (dropping relevancy scores below 9) demonstrates the prevalence of reoccurring word groups in both authors, further underlining Vergil’s debt to Lucretian diction. To list but a few examples: G. 2.411, obducunt sentibus and L. 5.207, sentibus obducat; G. 2.263, gelidaeque pruinae and L. 2.431, gelidamque pruinam; G. 2.217, Quae tenuem exhalat nebulam fumosque volucris and 6.104, tam tenues quam sunt nebulae fumique volantes; G. 2.367, amplexae stirpibus ulmos and L. 5.34, arboris amplexus stirpes; G. 2.36, fructusque feros mollite colendo and L. 5.1368, temptabant fructusque feros mansuescere terra.
Tesserae offers several additional tools (Other Tools). One can perform a multi-text search that enables users to select any number of texts to crosscheck against (available for Greek and Latin). This function does not, unfortunately, compensate for the Basic Search inability to search across two authors’ entire oeuvres at once (barring authors with only one work or collection of smaller works to their name, such as Catullus and Juvenal). Instead, the Multi-Text Search adds a new column to the search results with links to passages of works (previously selected by the user) containing “parallels” to the correspondences found between two main texts. The point of the Multi-Text Search is thus not to compare more than two texts, but rather to “allow you to see whether a particular parallel is unique to your two selected works, or whether there is a broader precedent for the repeated expression.” If one wished to examine Horace’s use of Terence’s Eunuchus in the Sermones, for instance, it might be prudent to crosscheck against works of Plautus to eliminate correspondences owing purely to archaic Latin comedic diction.
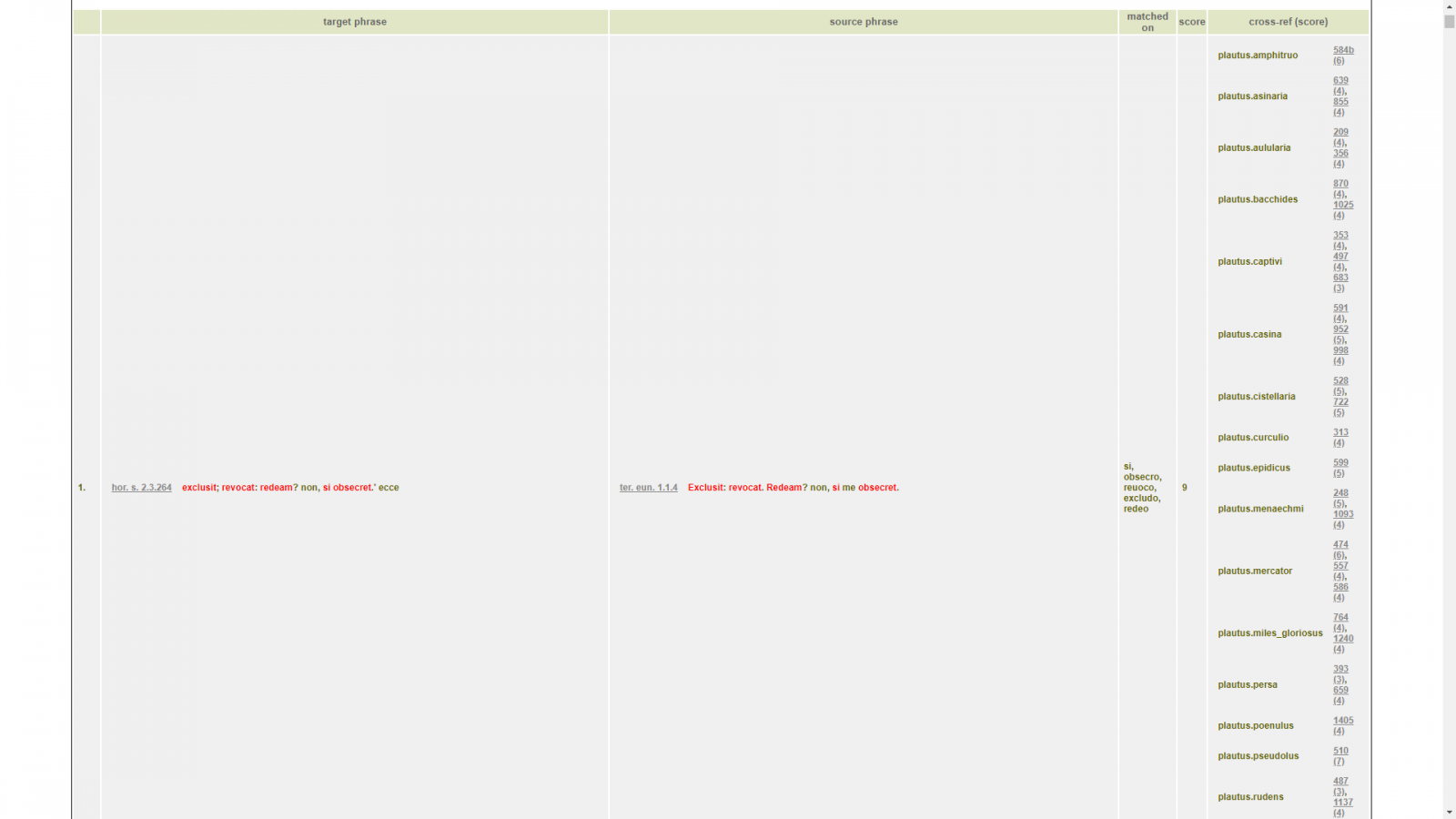
This function would be most helpful when used with the entire corpus, but unfortunately, I have found that doing so causes the program to crash (on both Chrome and Firefox).
A further tool, the “Tri-gram Visualizer,” presents users with a visualization of the prevalence of sequences of three letters within a single text (for Latin only). The user can customize the number of tri-grams to calculate and assign colors to three of the calculated tri-grams. The brighter the color, the more prevalent the tri-gram within a given section.

The “Full-Text Display” allows users to perform a basic or advanced search (Latin only) and displays results by highlighting in red the word pairs as they occur in the texts, which are presented in their entirety in two parallel, scrollable frames.
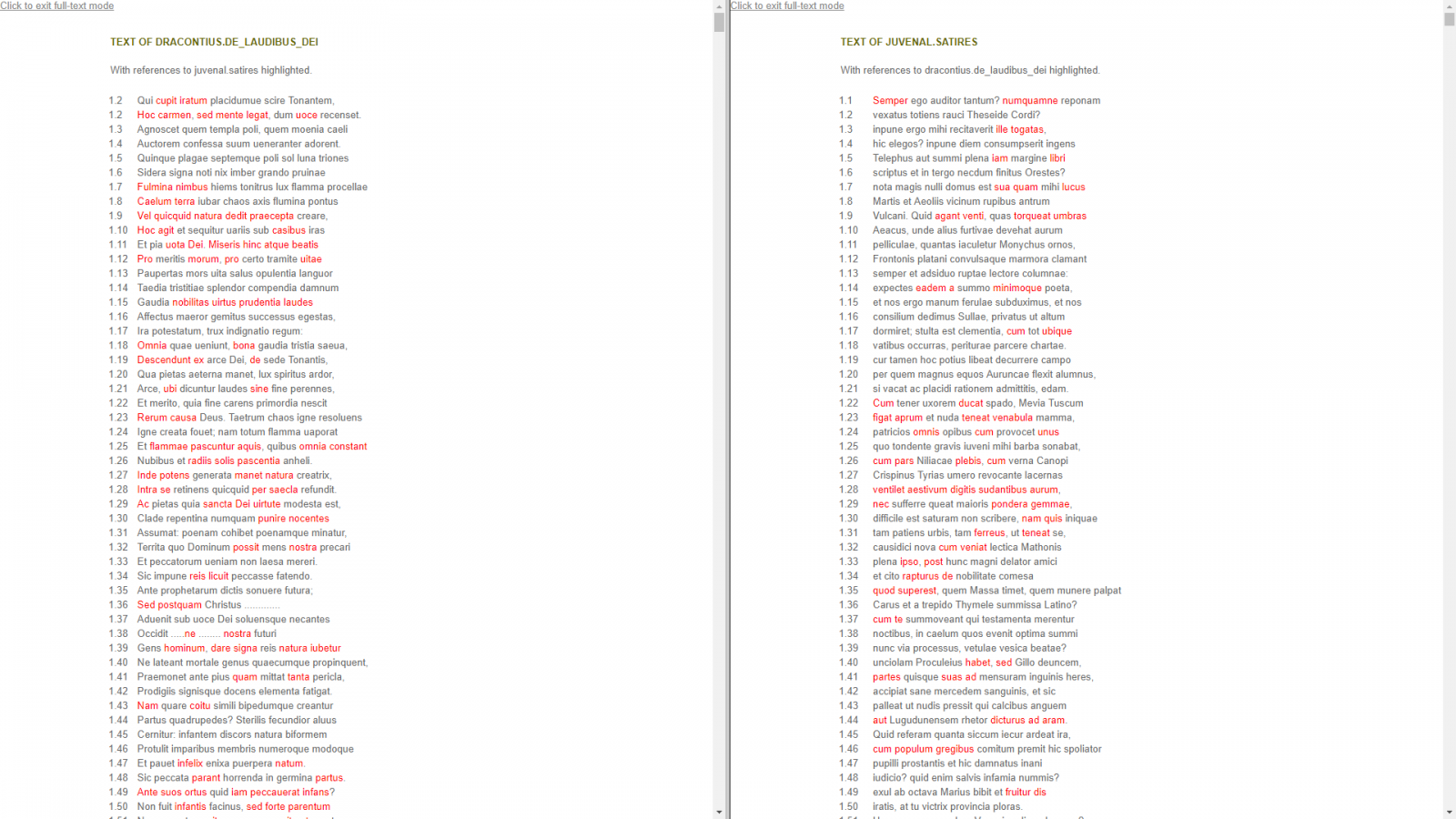
Overall, Tesserae’s main functionality—the ability to produce a list of (largely) relevant correspondences between two texts—makes for a useful tool for teaching purposes as well as research. In a classroom setting, it could easily be used to demonstrate stylistic influences; alternatively, students could utilize Tesserae on their own for an assignment on allusion and intertextuality. The website’s blog (last updated in August, 2017) highlights ways in which Tesserae can assist scholars in more advanced quantitative analyses, for example, in studying Ciceronian tendencies in the Vetus Latina as quoted by Augustine. Since much of Tesserae’s potential lies in examining works that have not received extensive commentarial apparatus, the available corpus remains the chief limiting factor: one would like to see a larger selection of medieval (both Latin and Byzantine), Renaissance, and Early Modern texts.
More easily realized desiderata include greater flexibility in selecting texts. It should be possible to search across entire oeuvres of authors—e.g., to find Terentian language in Augustine’s De civitate dei without having to perform a search for every comedy of Terence in combination with De civitate dei. Conversely, one should have the option of selecting individual poems. While it is possible to select individual books (e.g., Aeneid 4), it would be helpful to be able to select individual poems from among smaller works as well (e.g., Catullus 64).
In sum, Tesserae delivers on its promise to offer users a flexible and robust interface to search digital corpora of Greek and Latin texts. While it cannot replace more traditional methods for identifying intertextual relationships, it is a useful tool for a focused examination of verbal correspondences between two texts or small corpora based on quantitative methods.
Metadata:
TITLE: Tesserae
DESCRIPTION: web interface for exploring intertextual parallels in Greek and Latin texts.
URL: http://tesserae.caset.buffalo.edu/
NAME: Neil Coffee, Associate Professor of Classics, University at Buffalo; Walter J. Scheirer, Assistant Professor of Computer Science, University of Notre Dame; and Jean-Pierre Koenig, Professor of Linguistics, University of Buffalo.
PUBLISHER: [none]
PLACE: The University at Buffalo, the University of Notre Dame, and the University of Geneva.
COLLECTION TITLE: [none]
DATE CREATED: Current Version 3.1 (July 2015)
DATE ACCESSED: January 31, 2019
AVAILABILITY: Free
RIGHTS (license restrictions imposed on access to a resource): [none]
CLASSIFICATION:
databases, language processing, Greek, Latin, reference materials, texts, intertextuality.
Header image: Mosaic Tesserae, Byzantine (6th–15th century), Glass, gold and silver leaf. New York, Metropolitan Museum of Art, Accession Number:2016.11.1–.50. Image Credit: Metropolitan Museum, public domain. Image source: https://metmuseum.org/art/collection/search/708074
Authors

|
, Glass, gold and silver leaf. New York, Metropolitan Museum of Art, Accession Number:2016.11.1–.50. Image Credit: Metropolitan Museum, public domain. Image source: https://metmuseum.org/art/collection/search/7")