William Short
June 7, 2019
Can a computer understand the hendecasyllables of Catullus, the declamations of Seneca, or the letters of Pliny? Not yet, and maybe never in any conventional sense of this word. No one has succeeded so far in teaching a computer to comprehend language – that is, to reason about, generate, act upon and, importantly, communicate intentions through symbolic speech – let alone to appreciate texts written in a dead language with a sophisticated literary tradition. (Embodied cognitive science claims, in fact, that without a human body no computer can ever hope to achieve human understanding). But it is possible to represent the meanings of the Latin language in a way that can be manipulated and analysed by computers. The idea of training machines in these meanings forms the basis for the field of natural language understanding, which is a specialized kind of natural language processing (NLP) focused on modelling linguistic semantics.
NLP efforts for Greek and Latin have been given a huge boost by the creation of the Classical Language Tool Kit, by syntactic annotation projects like the Greek and Latin Dependency Treebank, and by classicists’ early embrace of computational-linguistic and corpus-linguistic methodologies. Still, tools for working computationally with the meanings of ancient texts are only now emerging. The CLTK includes an experimental library that can identify semantically similar words by comparing their lexical co-occurrence patterns. The Tesserae Project at the University of Buffalo has designed a search engine for discovering intertextual allusions cross-linguistically by abstracting away from surface lexical forms to the meanings of words. This system relies on correspondences between the glosses of words in bilingual dictionaries, making it possible to find semantic parallels between Greek and Latin texts, such as Vergil’s echo of Homer at the opening of the Aeneid, where causas . . . numine (1.8) recalls θεοί . . . αἴτιοι (Il. 3.164) at the level of word meaning.

But languages with relatively free word order and complex syntactic constructions will complicate any approach based on word embeddings. Similarly, extending the ‘pivot’ method of semantic search to other NLP applications may not be practicable. To begin with, it is vulnerable to the vagaries of translation. If Lewis & Short had chosen to define causa as ‘reason’ rather than ‘cause’, this word could not have been matched with αἴτιος. More problematicaly, it tends to ‘flatten’ the meanings of words. Causa and aition can probably be considered straightforward synonyms in the sense of ‘cause’, but – as Georges Dumézil showed – Latin numen does not mean ‘god’ in exactly the same way that θεός means ‘god’. In triangulating the meaning of these words via their English glosses, their rich semantic profiles are ignored. There is also the cost of translating terms to and from English. Finding semantic parallels in anything but the smallest corpora would likely incur prohibitive performance overheads.
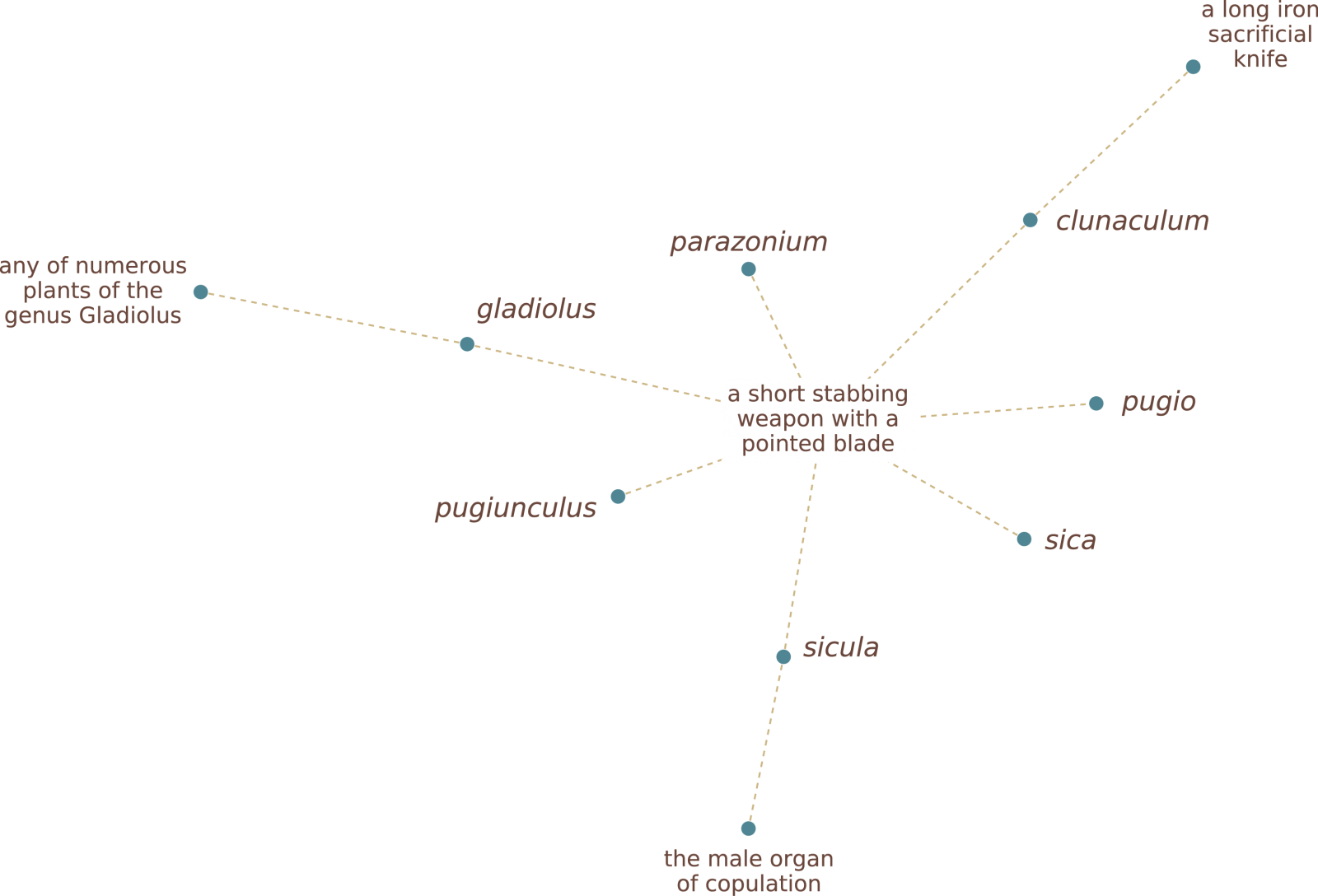
A different approach is being taken at the University of Exeter, where the development of Latin WordNet has been launched. Latin WordNet is lexico-semantic database, in which this language’s “open-class” vocabulary items – its nouns, verbs, adjectives, and adverbs – are assigned to sets of cognitive synonyms (synsets), which represent the discrete concepts that characterize the senses of these words. Synsets are linked together through different kinds of semantic relations, such as antonymy, hypernymy, and hyponymy, and lexemes are linked through derivational relations. Synsets are also grouped together into larger conceptual fields (semfields). The Latin word sica, for example, is connected through the synset glossed as ‘a short stabbing weapon with a pointed blade’ (within the ‘Arms & Armour’ semfield) to gladiolus, parazonium, sicula, pugio, and clunaculum, as well as to sicilicula, sicilimenta, sicilius, sicilio, and sicarius through derivational linkages. Each of these items is in turn linked to others, creating a densely interconnected and multi-layered conceptual “map”. Besides its literal sense, the diminutive sicula can also be used to denote the membrum virile – and so links through this sense to entirely different portion of the network!
Latin WordNet is akin, in this sense, to the kinds of lexicographic resources classicists already normally employ. Certainly, it can be viewed – and utilized – as a simple dictionary, or as something like Döderlein’s Handbook of Latin Synonyms. It captures subtle distinctions in words’ meanings and can include information about how these meanings change diachronically. However, the WordNet goes far beyond the printed lexicon by representing the meanings of the Latin language in machine-interpretable form (not primarily as strings of letters), and by providing a means of ‘traversing’ the lexicon programmatically by following determined paths of semantic and lexical relation. It is envisioned as a wide-ranging and comprehensive knowledge-bank that will aggregate information not only about Latin words and their meanings, but also about etymological relations and word formation – as well as the kinds of large-scale figurative patterns that organize meanings in this language at a level above any particular word’s semantic structure.
By creating a machine-friendly representation of Latin as a symbolic system, we can harness the extraordinary processing power of computers to our own interpretive ends. To begin with, the Latin WordNet could help open Greek and Latin texts to entirely new kinds of queries based on their semantic properties. This means it will be possible to search for occurrences of specific senses in texts. For example, someone interested in Roman ‘courage’ will be able to find all occurrences of this concept in Latin literature – independent of how it might be expressed lexically (as virtus, animus, fortitudo, audacia, or ferocia) – simply by searching for its English gloss. This would make identifying semantic intertextualities – the ways in which one text creates new meanings by reworking the themes and ideas (not merely the verbal elements) of other texts – almost trivial. Complex searches involving lemma-based and bare syntactic queries will also be possible, boosting ‘constructional’ approaches to ancient language semantics. Because the WordNet will enable searching the corpus via English – or French, Italian, or Spanish – it will allow speakers of different languages to explore ancient literature even without expert knowledge of Latin.

Similarly, the Latin WordNet could be used to teach a computer to identify and even predict patterns of meaning at different levels of text structure: in expressions, in passages, or indeed across whole works or collections of works. This could help support the reconstruction of fragmentary epigraphic or papyrological texts, and help resolve questions of interpretation in literary studies. Almost all NLP algorithms presently face the challenge of word sense disambiguation – to be really useful, they need to determine the correct meaning of a particular word in context – and this kind of information will be furnished by the Latin WordNet. In pedagogy, it could facilitate students’ learning of vocabulary – by illustrating how words and their meanings cluster together in coherent systems – as well as teachers’ production of classroom exercises – by generating “cloze” activities in which students must infer the meanings of one text from other similar texts. Thus, while we probably will not be communicating with a Latin-speaking artificial intelligence any time soon, by enabling computers to work algorithmically with meanings as they can with other kinds of symbols, Latin WordNet can empower us to use computers to better understand the meanings expressed by the ancient Romans through their linguistic artifacts.
The original Latin WordNet, created through an automated process for the Fondazione Bruno Kessler’s MultiWordNet Project in 2008, consisted of about 9,000 words. Under the direction of Dr. William Michael Short, and in collaboration with the Linking Latin Project, a team at Exeter is now manually revising and expanding it to include over 70,000 words covering the archaic through medieval periods of the language. In partnership with the University of Genoa, Dr. Short’s team is also building a Latin metaphor dictionary (Lexicon Translaticium Latinum) on top of the WordNet, by adding rich information about metonymic and metaphorical structures in the language. Though still a work-in-progress, this Latin WordNet ‘2.0’ is now available at http://latinwordnet.exeter.ac.uk/ and its data can be accessed on the Web or through an intuitive API. Enquiries are welcomed from anyone interested in making use of the WordNet or in contributing to its development.
Authors

|
